Exploration first
I’ve always believed that before classifying, we need to explore. FactoClass
comes from that idea.
This work is part of what I did while I was a Statistics student at the
Universidad Nacional de Colombia. It was my first steps as a statistician and programmer, developed
under the guidance of Campo Elías Pardo and inspired by Lebart and colleagues.
Method: factorial + clustering
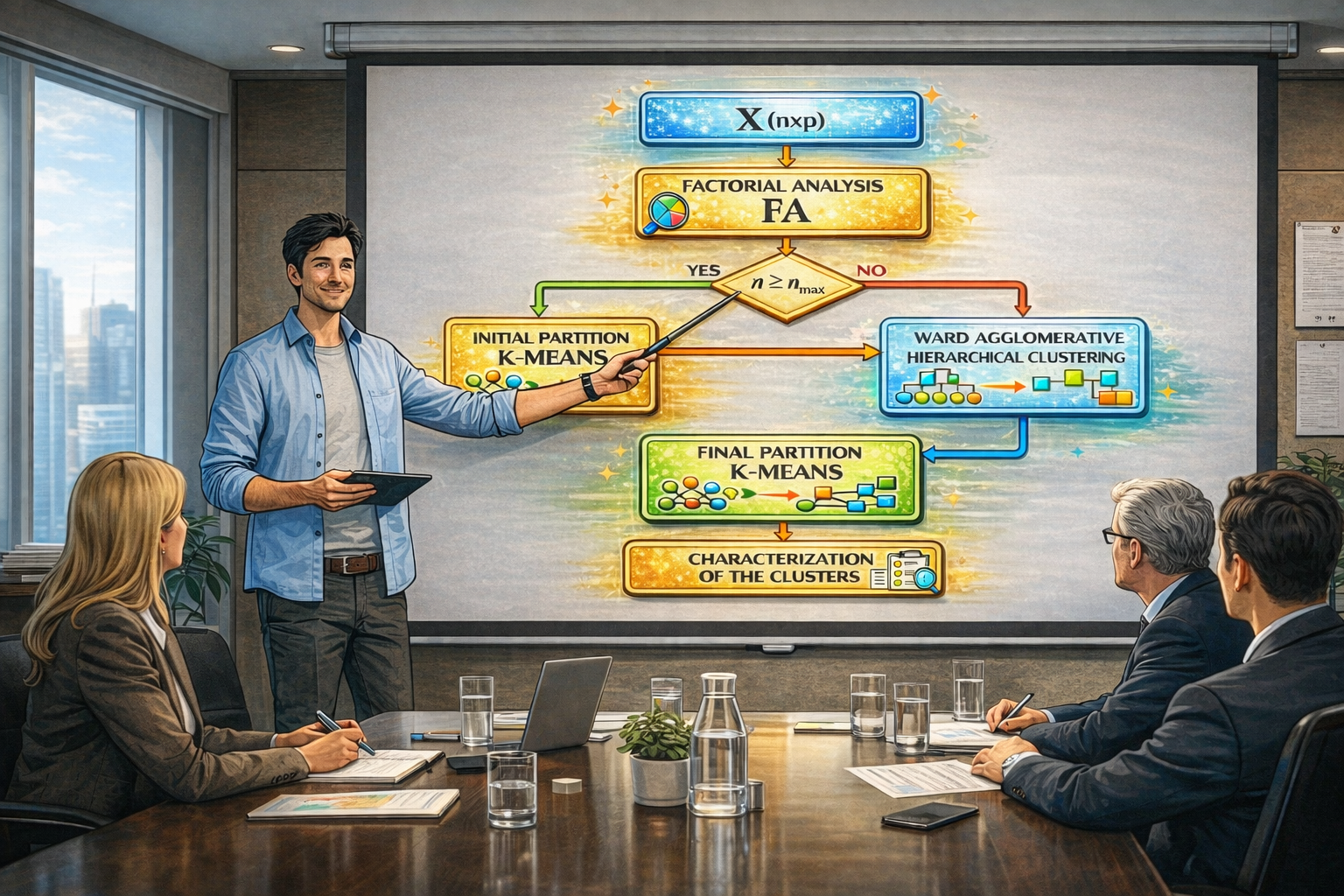
The package implements a strategy that combines factorial methods and cluster
analysis to explore complex data tables. First, a factorial space organizes variability and reduces
noise; then clustering follows—initial partitions, Ward hierarchical aggregation, and a final K-means
consolidation—all within that shared space.
Applications
FactoClass is useful when the objective is exploratory rather than predictive,
and when understanding internal structure comes before modeling. It fits complex multivariate tables
(quantitative, categorical, or frequency) across social, demographic,
territorial, or survey-based datasets. It helps identify meaningful
groups while preserving interpretability, making it applicable to population profiling,
market segmentation, behavioral analysis, academic research
and teaching focused on multivariate exploration, and more.
Why it matters
Looking back, this work reminds me that deeply understanding and exploring the
nature of things is what allows us to classify them in a meaningful way.
Explorar primero
Siempre he creído que antes de clasificar hay que explorar. FactoClass nace
de esa idea.
Este trabajo hace parte de lo que hice como estudiante de Estadística en la
Universidad Nacional de Colombia. Fueron mis primeros pasos como estadístico y programador, bajo la
guía de Campo Elías Pardo e inspirado en la metodología de Lebart y sus colegas.
Método: factorial + clustering
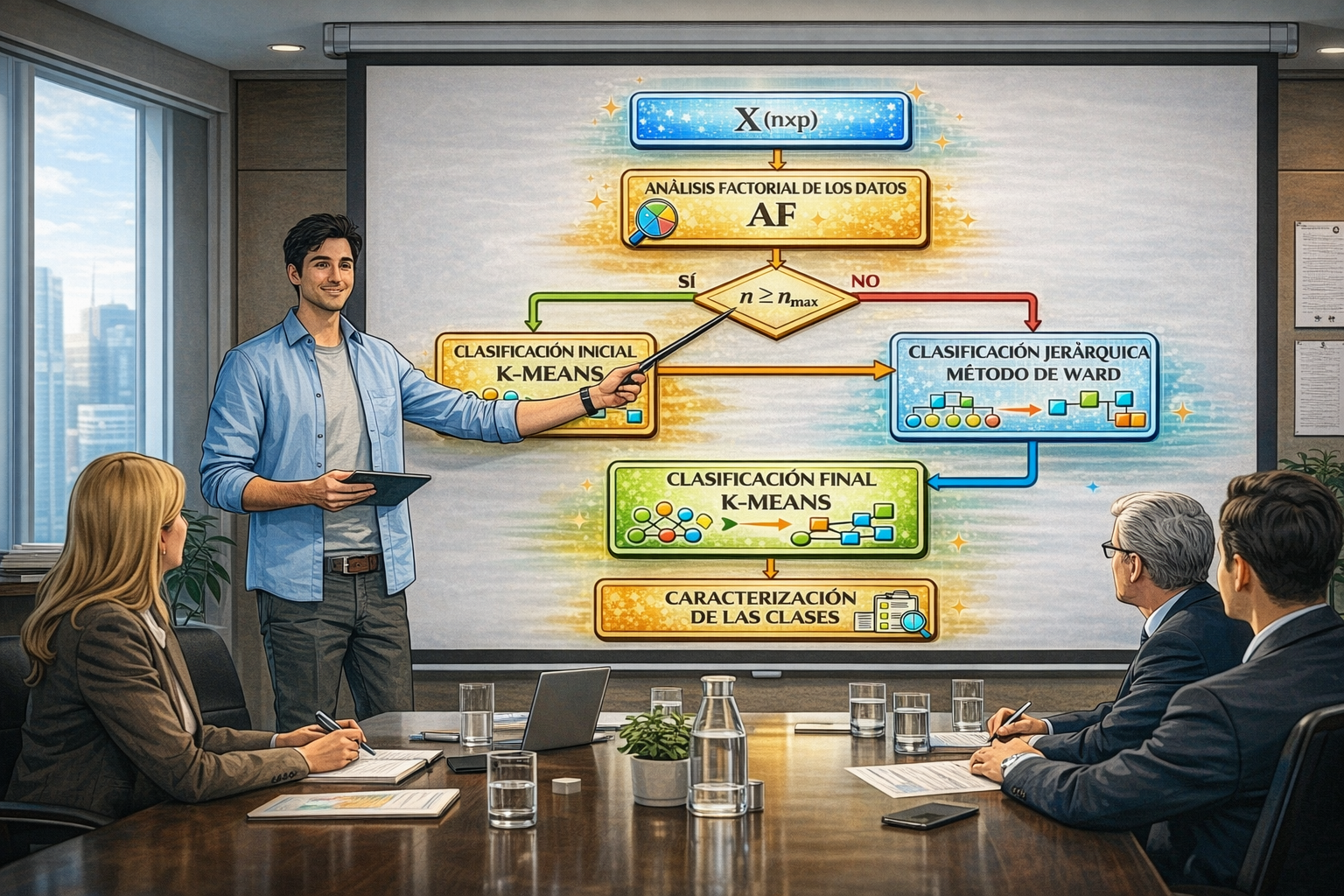
El paquete implementa una estrategia que combina métodos factoriales y análisis
de clusters para explorar tablas de datos complejas. Primero se construye un espacio factorial que
organiza la variabilidad y reduce ruido; luego viene el clustering—particiones iniciales, agregación
jerárquica de Ward y consolidación final con K-means—todo en ese mismo espacio.
Aplicaciones
FactoClass es especialmente útil cuando el objetivo es exploratorio más que
predictivo, y donde comprender la estructura interna de los datos precede al modelado. Funciona bien
con tablas multivariadas complejas—datos cuantitativos, categóricos o de frecuencias—en contextos
sociales, demográficos, territoriales o de
encuestas. Ayuda a identificar grupos con sentido sin perder interpretabilidad,
aplicable a perfiles poblacionales, segmentación de mercado,
análisis de comportamiento, investigación académica y enseñanza de
métodos exploratorios multivariados, entre otros.
Por qué importa
Mirando atrás, este trabajo me recuerda que entender y explorar a fondo la
naturaleza de las cosas es lo que permite clasificarlas de manera significativa.